While I consider myself to be a proficient Python programmer generally, I have definitely used R much more in the recent past. R is my preferred language for doing data-centric tasks but I would like to improve my fluency with tools in the Python Data Analysis ecosystem.
In particular, I intend to make a concerted effort to learn the scikit-learn library for Machine Learning in Python. In this notebook, I work through simple examples of using scikit-learn to do linear regression.
I use a data set from the US Department of Energy. The goal of the regressions here is to formulate models to predict the fuel efficiency (in miles per gallon) of vehicles in the data set.
The input file has been filtered from the original data I obtained from fueleconomy.gov to contain non-electric model year 2020 vehicle. I have made the data available in csv format via a public Github repository.
Reading in data
The code below
reads in the data using the
read_csvfunction of thepandaslibraryuses the
typeto verify the class of the object that the data has been stored to
import pandas as pd
cars2020 = pd.read_csv("https://raw.githubusercontent.com/thisisdaryn/data/master/ML/cars2020.csv")
type(cars2020)<class 'pandas.core.frame.DataFrame'>We can use the head method of the DataFrame class to view the first few rows:
cars2020.head() make model mpg ... fuel atvType startStop
0 Acura ILX 27.9249 ... Premium None N
1 Acura MDX AWD 22.0612 ... Premium None N
2 Acura MDX AWD A-SPEC 21.3495 ... Premium None N
3 Acura MDX FWD 23.0000 ... Premium None N
4 Acura MDX Hybrid AWD 26.8723 ... Premium Hybrid Y
[5 rows x 14 columns]Simple linear regression
First, I attempted to do a simple linear regression, fitting a linear model of mpg vs disp. The disp variable is the engine’s displacement, the sum of the volume swept by all the pistons of a vehicle’s engine. The engine displacement is a measure of the size of a car’s engine.
Getting the variables of interest
We can get the variables we are interested in by extracting the disp and mpg columns of the data.
disp = cars2020[["disp"]]
mpg = cars2020[["mpg"]]An exploratory scatter plot
Next, I made an exploratory scatter plot of the relationship between the two variables, using matplotlib.pyplot
import matplotlib.pyplot as plt
plt.scatter(disp, mpg, alpha = 0.25)
plt.title("MPG vs engine displacement", fontdict={'fontsize': 6, 'fontweight': 'medium'})
plt.show()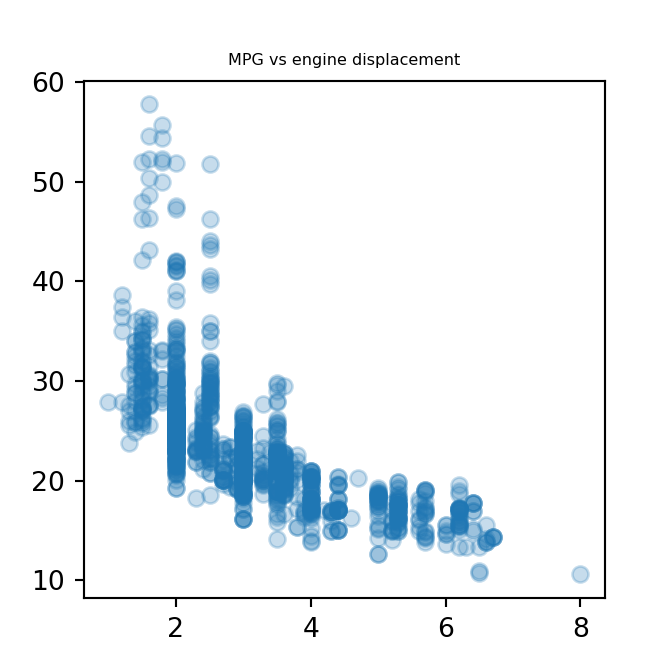
Modeling
To carry out the actual linear regression, we use the scikit-learn library.
- Import
linear_model - Instantiate an object of type
LinearRegression
from sklearn import linear_model
regr = linear_model.LinearRegression()
type(regr)<class 'sklearn.linear_model._base.LinearRegression'>Next fit the model with the vectors of predictors (X) and outcomes (Y)
regr.fit(disp, mpg)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)The above function call causes the intercept_ and coef_ properties of regr
to be the intercept and slope terms of the model.
We can print the values of the model parameters:
print("Model 1\n", "Intercept: ", regr.intercept_,"\nCoefficients", regr.coef_)Model 1
Intercept: [34.05220566]
Coefficients [[-3.4131261]]Interpreting the model paramters
Briefly, we can think about how these parameters are interpreted:
Start with an MPG of 34.05
for every Liter of engine displacement subtract 3.41 MPG from the estimate
Engines with greater values for engine displacement will be predicted to have lower levels of fuel efficiency.
Note that two cars with the same engine displacement necessarily will have the same predicted fuel efficiency from the model. This is an inevitability of using only a single explanatory variable in the model.
Showing the regression line
The code below manually superimposes the regression line onto the scatter plot of mpg vs displacement
plt.scatter(disp, mpg, alpha = 0.2)
plt.plot([0,8], [regr.intercept_, regr.coef_*8 + regr.intercept_], "--", color = "red")
plt.title("MPG vs engine displacement", fontdict={'fontsize': 6, 'fontweight': 'medium'})
plt.show()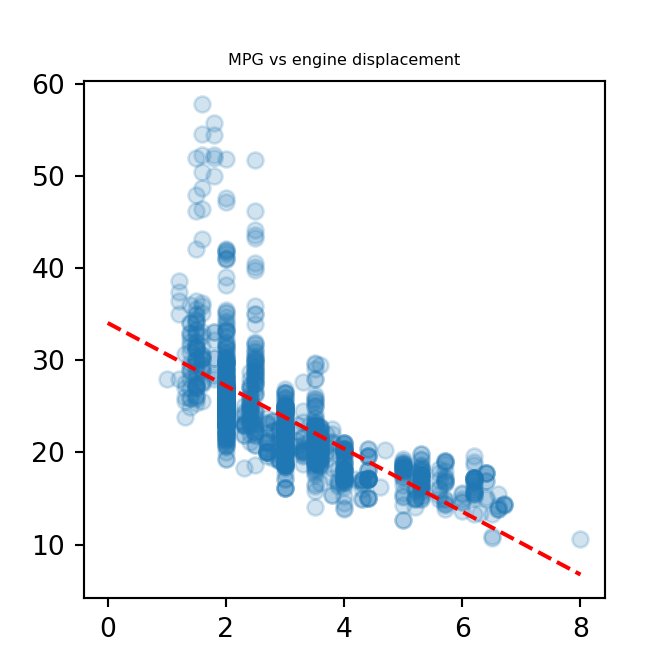
Getting the model predicted values
We can use the predict method of the LinearRegression class to return the vector of model outputs for each element of the input vector, disp
model1_mpg = regr.predict(disp)Plotting model vs actual
One way to compare the model predicted values to the actual values is to plot them against each other in a scatter plot.
plt.scatter(mpg, model1_mpg, alpha = 0.2)
plt.title("Model MPG vs Actual MPG (model: mpg~disp)", fontdict={'fontsize': 6, 'fontweight': 'medium'})
plt.show()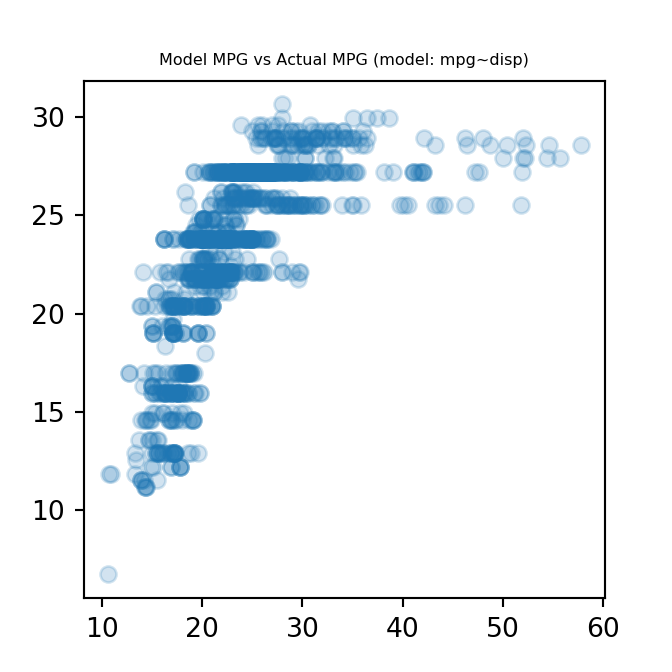
We can modify the above plot by adding a diagonal line with intercept, 0, and slope, 1. A point lying on this line would indicate that the value predicted by the model and the actual value were equal. A model that fits the data closely, would thus have a scatter plot in which the points were typically close to the diagonal line.
plt.scatter(mpg, model1_mpg, alpha = 0.2)
plt.plot([0,60], [0,60], "--", color = "red")
plt.title("Model MPG vs Actual MPG (model: mpg~disp)", fontdict={'fontsize': 6, 'fontweight': 'medium'})
plt.show()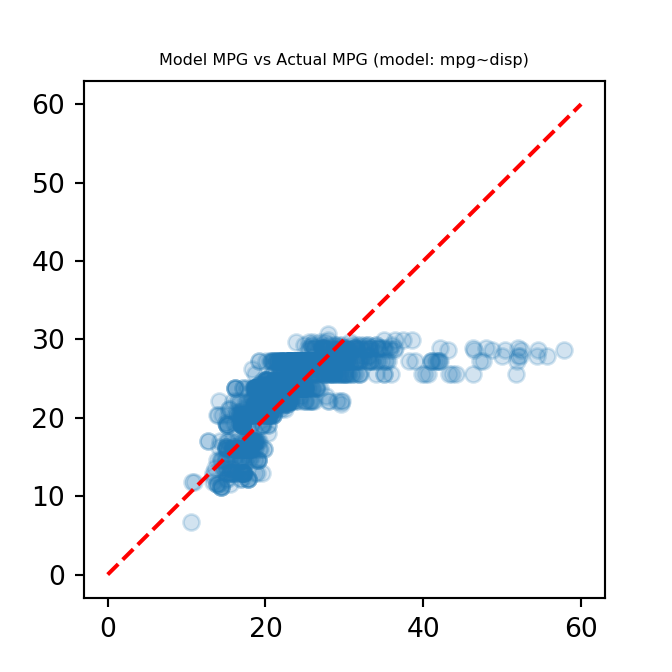
Here we can see that the model does not do as well to predict the vehicles with high fuel-efficiency. Next, I will try to run a multiple linear regression model, with three additional variables, to perhaps get a better model fit.
Multiple Linear Regression
Next, we attempt to calibrate a multiple linear regression model: a linear model with multiple predictors.
The 4 predictors being used in this multiple linear regression model are:
disp, engine displacement in Liters
transmission, transmission type: Automatic, CVT, or Manual
drive, drivetrain: 4WD, AWD, FWD PT 4WD, or RWD
atvType, alternative technology type: Diesel, FFV, Hybrid, None, or Plug-in Hybrid
First, extract the variables of interest by name:
cars_vars = cars2020[["disp", "transmission", "drive", "atvType"]]We can look at the first few rows using DataFrame.head once again
cars_vars.head() disp transmission drive atvType
0 2.4 Manual FWD None
1 3.5 Automatic AWD None
2 3.5 Automatic AWD None
3 3.5 Automatic FWD None
4 3.0 Manual AWD HybridCreating dummy variables
As some of these variables are categorical, we first have to create dummy variables before fitting the model:
cars_vars = pd.get_dummies(cars_vars, drop_first=True)
cars_vars.head() disp transmission_CVT ... atvType_None atvType_Plug-in Hybrid
0 2.4 0 ... 1 0
1 3.5 0 ... 1 0
2 3.5 0 ... 1 0
3 3.5 0 ... 1 0
4 3.0 0 ... 0 0
[5 rows x 11 columns]If the drop_first argument had not been set to True there would be a dummy variable created for each level of each categorical variable. This is not necessary: it suffices to use one level as a reference level and to indicate only if a subject vehicle belongs to any of the other levels.
As it stands, with drop_first=True, dummy variables are created for all but one level of each categorical variable.
Fitting the multiple linear regression model
A call to LinearRegression.fit with the predictors and output data will perform the linear regression
regr_2 = linear_model.LinearRegression()
regr_2.fit(cars_vars, mpg)LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)The model coefficients are now stored in the intercept_ and coef_ properties of the regr_2 object.
Viewing model parameters in multiple linear regression
As before, we can view the model-fitted parameters:
print("Model 2\n", "Intercept: ", regr_2.intercept_,"\nCoefficients", regr_2.coef_)Model 2
Intercept: [30.36387263]
Coefficients [[-2.37613998 5.07512162 0.72912462 0.3598029 4.85016323 0.13808905
1.31936111 -2.59373099 4.50478963 -2.5394815 1.63706936]]model_params = zip(cars_vars.columns, regr_2.coef_[0])
print("Intercept: ", regr_2.intercept_[0])Intercept: 30.363872634275147for param in model_params:
print(param[0], ":", param[1])disp : -2.376139975429364
transmission_CVT : 5.075121623348058
transmission_Manual : 0.7291246234166626
drive_AWD : 0.3598029024265794
drive_FWD : 4.850163234058179
drive_PT 4WD : 0.13808904559734075
drive_RWD : 1.3193611105192886
atvType_FFV : -2.5937309931581316
atvType_Hybrid : 4.504789629801591
atvType_None : -2.539481497779101
atvType_Plug-in Hybrid : 1.6370693619393155Retrieving model-predicted values
Now use LinearRegression.predict to get the model-predicted values for each vehicle in the training data.
model2_mpg = regr_2.predict(cars_vars)Plotting model vs actual values
And once again, use matplotlib.pyplot to plot the model-predicted values vs the actual mpg values in the training data.
plt.scatter(mpg, model2_mpg, alpha=0.25)
plt.plot([0,60], [0,60], "--", color = "red")
plt.title("Model MPG vs Actual MPG (model: mpg~disp+transmission+drive+atvType)", fontdict={'fontsize': 5, 'fontweight': 'medium'})
plt.show()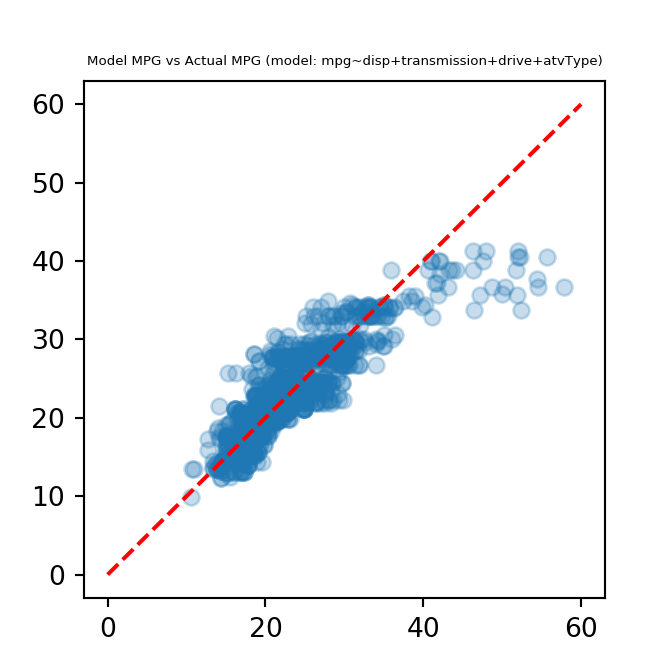
This model fits the training data more closely that the univariate model. In particular the vehicles with higher mpg are now closer to the diagonal line.
In future notebooks, I will utilise more of the functionality and methods available in scikit-learn.